Replication and Last Mile Transactions
Imagine this scenario: the datacenter was on
fire. All components—servers,
storage, network—are destroyed. You can’t salvage anything of
value. What
happens to the data you need to continue your business?
Fortunately you have a
disaster recovery plan. You replicate the database to a remote
datacenter using
either Data Guard (from Oracle), or some storage level technology
such as EMC’s
SRDF. So the database comes up on the remote site; but there is a
problem.
Since you used asynchronous replication (such as maximum
performance mode in
Data Guard), not all changes have made it to remote site. The
final few
changes, usually known as last mile transactions were yet to be
shipped to the
remote site when the disaster struck. These are lost forever in
the fire. While
you do have a database at the remote datacenter, and that database
is almost
complete—the operative word is “almost”; not 100%, mind you—some data is inevitably
lost. What if
you can’t afford to be “almost” complete? Organizations such as
financial
institutions, hospitals, manufacturing concerns and airlines where
losing data is
simply not an option, this is not a luxury they can afford. Even
in case of
other organizations where data loss may not be as unacceptable,
the loss of
data creates a sense of uncertainty, since you don’t know exactly
what was lost.
If you need to be 100% certain that all data is
available at
the remote site, what would you do?
It’s easy, using synchronous replication. All changes on the primary database are reflected on the remote database site in real time. If you used Data Guard, you would have run it in maximum protection mode. In that case, Oracle would have committed the changes in the remote database before confirming the commit at the local site. When the primary site is gone, the remote site is available with 100% of the data. Bye bye, “almost”.
Brilliant. So, why didn’t you do it? Better yet, why doesn’t everyone do it, since it is that simple? Data loss could be unacceptable in the worst case and unsettling at best. Why accept it?
Synchronous Replication
Well, there is a pesky little detail.
Synchronous
replication means the network connectivity has to be rock solid.
Networks have three
general characteristics: throughput
(how much data they can pump. Imagine a three lane highway
compared to a single
lane local road), latency
(how much
time passes to process the data; not the actual speed. For
instance, the car on
the highway may travel at 70 miles per hour; but it will be a few
minutes spent
on the ramp to the highway) and reliability
(does the data move from point A to point B with 100% accuracy or
it has to be
re-transmitted a few times).
Synchronous replication requires the throughput to be very high (to support the large amounts change at least during bursts of activity), latency to be very low (otherwise the remote site will get the data late and respond to the primary even later, causing the primary to hold off the commit) and extremely reliable (otherwise the primary may think the remote site is not accessible and therefore shutdown itself to protect the data). If you run the Data Guard in maximum protection mode, you are essentially telling Oracle to make sure that the remote site has absolutely, positively, undoubtedly (add any other adjective you can think of) received the change and has committed.
Synchronous replication requires the throughput to be very high (to support the large amounts change at least during bursts of activity), latency to be very low (otherwise the remote site will get the data late and respond to the primary even later, causing the primary to hold off the commit) and extremely reliable (otherwise the primary may think the remote site is not accessible and therefore shutdown itself to protect the data). If you run the Data Guard in maximum protection mode, you are essentially telling Oracle to make sure that the remote site has absolutely, positively, undoubtedly (add any other adjective you can think of) received the change and has committed.
If Oracle can’t ensure that because of any reason, such as not getting the response in time due to a less reliable network, what choices does it have? If it allows further data changes, the changes are not there at the remote site yet. At this time if the primary database fails, the data is gone. Therefore Oracle has no choice but to shut down the primary database to stop any changes coming in. It’s maximum protection, after all, and that’s what you have instructed it to do.
So, if you decide to use maximum protection, you have to use a high throughput, low latency and extremely reliable network infrastructure. Most public commercial network infrastructures are not. Either you have to contract a commercial carrier to provide this elevated level of service, or build your own, such as using dark fiber. The costs of the network infrastructure become exponentially high, especially when the remote site is farther away from the primary. In many cases, the cost of the network itself may be several times that of the database infrastructure it protects. Owing to the cost limitations, you may be forced to locate the remote site close by, e.g. in New York City and Hoboken, NJ. It will still be exceedingly expensive; and it may not offer the same degree of protection that you expect. These two cities are close enough to be in the same exposure area of disasters such as floods, hurricanes, war and so on. The farther away the remote site is, the more protected your data is; but so is your cost. Could you accomplish no data loss without this expensive proposition?
Until now, the decision was really black and white. If you want no data loss at all, you have no choice but to go for a super expensive network solution. Many companies can’t justify that high sticker price and therefore settle for potential data loss. Many, in fact, make detailed plans as a part of the business continuity efforts on handling this lost data.
It’s assumed that zero data loss is synonymous with expensive network. If you don’t have a high throughput, low latency, highly reliable network, you have to live with some data loss.
Here is the good news. No, it doesn’t have to. Now, it’s possible to have the cheaper commoditized public network infrastructure and still have complete data protection. Allow me to explain.
Data Protection in Oracle
In Oracle, the data files are written
asynchronously at
different intervals unrelated to the data changes and commits. In
other words,
when you commit a change, the data files may not have that changed
data. In
fact the change occurs in the memory only (called a buffer cache)
and may not
exist in the data files for hours afterwards. Similarly when you
make a change
but not commit, the data can still be persisted to the data files.
Let me
repeat that: the data files are updated with the changed data even
if you
didn’t commit yet. This is the reason why if you have a storage or
operating
system level replication solution—even synchronous—replicating the
data files,
the remote site may or may not have the data, even hours after the
change.
How does Oracle protect the data that was
changed and
committed but in the memory, if the data files do not have them?
It captures
the pre- and post-change data and packages them into something
called redo blocks.
Remember, these have nothing
to do with data blocks. These are merely changes created by
activities
performed on the database. This redo data—also known as redo
vector—is written to
a special area in memory called log
buffer. When you commit, the relevant redo blocks from the
log buffer are
written to special files in the database called redo log files, also known as online
redo log files. The commit waits until this writing—known as
redo flushing—has ended.
You can check
the Oracle sessions waiting for this flushing to complete by
looking at the
event “log file sync”. Since the changes—most importantly—committed changes are recorded in the redo log
files, Oracle does not
need to rely on the memory alone to know which changes are
committed and which
are not. In case of a failure, Oracle examines the redo logs to
find these
changes and updates the data files accordingly. Redo logs are very
small
compared to the data files.
By the way, redo flushing also occurs at other
times: every
three seconds, every filled 1 MB of log buffer, when a third of
the log buffer
is full and some other events; but those additional flushes merely
make sure
the redo log file is up to date, even if there is no commit.
As you can see, this redo log file becomes the most important thing in the data recovery process. When a disaster occurs, you may have copies of the data files at the remote site (thanks to the replication); but as you learned in the previous section the copies are not useful yet since they may not have all the committed changes and may even have uncommitted changes. In other words, this copy is not considered “consistent” by Oracle. After a disaster, Oracle needs to check the redo log files and apply the changes to make the data files consistent. This is known as a “media recovery”. You have to initiate the media recovery process. In case of a synchronous replication at storage or Operating System level, the redo logs are perfectly in sync with the primary site and Oracle has no trouble getting to the last committed transaction just before the failure. There will be no data lost as a result of the recovery process. In case of Data Guard with maximum protection, this is not required since the changes are updated at the remote site anyway. But what about your cheaper, commodity network with asynchronous replication? The redo logs at the remote site will not be up to date with the primary site’s redo logs. When you perform media recovery, you can’t get to the very last change before the failure, simply because you may not have them. Therefore you can perform a recovery only up to the last available information in the redo at the remote site. This is known as “incomplete” media recovery, distinguished from the earlier described “complete” media recovery. To complete the media recovery, you need the information in the redo log files at the primary site; but remember, the primary site is destroyed. This information is gone. You end up with a data loss. Perhaps even worse, you won’t even know exactly how much you lost, since you don’t have the access to the primary redo log files.
Now, consider this situation carefully. All you need is the last redo log file from the primary database to complete the recovery. Unfortunately the file is not available because it’s destroyed or otherwise inaccessible since the site itself is inaccessible. This tiny little file is the only thing that stays between you and complete recovery. What if you somehow magically had access to this file, even though the rest of the data center is gone? You would have been able to complete the recovery with no data loss and looked like a hero and that too without a synchronous replication solution with super expensive network.
Enter the Black Box
Oracle’s redo data can be written to multiple
files at the
same time. This is called a redo log group and the files are
called members.
Log flushing writes to all members before confirming the flush. As
you can see,
all members of a group have the same data. Multiple members are
created only
for redundancy. As long as one member of a group is available,
Oracle can use
it to perform recovery. This is where the new tool from Axxana comes in. It is a storage device—named Phoenix—where you create the second member of the
redo log groups.
The first member of the group is on your normal storage as usual.
When disaster
strikes and nukes the primary site, you have a copy of the
all-important redo
log from the Phoenix system.
This is where the first benefit of Phoenix
systems comes in.
The storage is not just any ordinary one. It’s encased in a
bomb-proof,
fire-proof and water-proof container which preserves the internal
storage from
many calamities. The storage has normal connectivity such a
network port to
connect a network as a NAS and a fiber port to connect to a fiber
switch as a
SAN. Under ordinary circumstances you would use these ports to
connect to your
infrastructure system and use the storage. After a disaster, due
to the
indestructible nature of the enclosure, this storage will most
likely be
intact. All you have to do is to access the data from it and
perform a complete
recovery. No data needs to be lost.
But how do you get to the information on the Phoenix system? This is where the second benefit comes in. The Phoenix system transfers its data to another component of the Phoenix system at the remote site. The Phoenix system creates a replica of the required redo logs at the remote site. Since the only data on it are the small redo log files, the amount to transfer is very little and does not put a toll on your other network infrastructure.
Note a very important point: Phoenix system does not perform any transfer of data during normal operation. It’s only during a disaster the system transports the required redo log files to complete a 100% recovery at the remote site.


But it still depends on getting the data out of
the Phoenix
system that was at the primary site. What if the disaster site is
physically
inaccessible or it is infeasible to physically transport the
Phoenix system to
a location where it can be connected to your network? It’s quite
possible in
case of floods, hurricanes or other natural disasters or manmade
ones like war
or strikes. The network cables are also likely out of commission
after a
disaster. Without that access, how can Phoenix system extract the
needed last
mile transactions from the primary site—you might ask.
No worries; there is a cellular modem built
into the Phoenix
system that allows you to connect to it from the remote site and
transfer the
data over a cellular network wirelessly. The system also has its
own battery
that allows it to stay operational even when external power is
gone—a common
occurrence in almost any calamity. What’s more: the transfer of
data after the
disaster can also utilize this cellular connectivity; so you may
not even need
to physically connect to this storage at the primary site (now
defunct due to
the disaster) to your network. The data you need to perform the
complete
no-data-loss recovery may already be transferred over to the
system at the
remote site and is waiting for you. In any case, you have access
to the data.
And all this comes without the need to invest in synchronous
replication and expensive
network infrastructure.
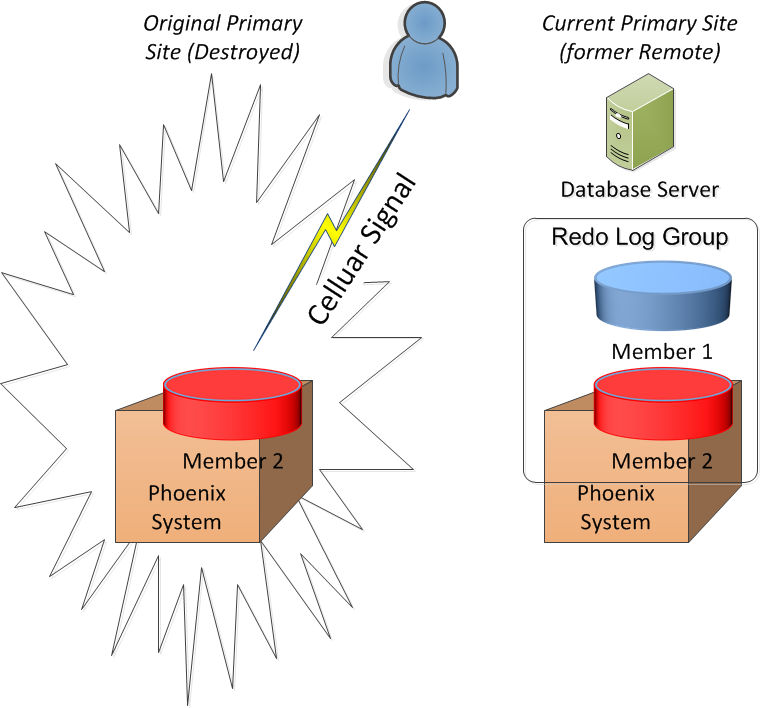

In summary, assuming the primary site is gone
and you are
using a cheaper asynchronous network, the remote site will be
partially
up-to-date and the last mile transactions will be lost with the
loss of the
primary database. However, since you used the disaster-proof
Phoenix system for
an additional member of the redo log group, the last mile
transactions will be
intact in that system; the remote system won’t have it yet. At
this point you
have multiple options:
1)
If the network
infrastructure between primary
and remote sites is still operational (rare; but possible),
Phoenix system data
transfer creates the copy of redo logs at the remote site
automatically. With
this in place, you can perform a complete database recovery. Data
Loss: 0%.
2)
If the network
infrastructure is not
operational, Phoenix will automatically engage the built-in
cellular modem and
initiate the data transfer to the remote site. It will be slow;
but the amount
of data to be transferred is small; so it won’t matter much. Once
that is
complete, your recovery will be complete with 0% data loss.
3)
If you don’t have cellular
access either, but
have access to the physical Phoenix system device, you can mount
it on your
network and perform a complete recovery.
As I started off, this is a very simple and
elegant out of
the box solution to a complex problem. It opens up possibilities
for a
no-data-loss recovery scenario in case of a disaster, where the
option didn’t
even exist. In a future post I will describe in detail my hands on
experience
with screenshots, scripts, etc. with the Phoenix system. Stay
tuned.
More about Axxana: www.axxana.com
2 comments:
I think this article is useful to everyone.
สล็อต Slot online ฟรีเครดิต ไม่ต้องฝาก 2019"
ซื้อหวยออนไลน์ เว็บไหนดี"
หวยออนไลน์ lottovip"
หวยฮานอย เล่นยังไง"
Interesting article about databases, it is very entertaining.
_________________________________
I work with roberta model ai
Post a Comment